
Jeśli myśleliście, że aparat w waszym telefonie nadaje się tylko do uwieczniania rozmazanych wspomnień z koncertów, naukowcy właśnie wyprowadzili was z błędu, zamieniając go w pełnoprawny skaner 3D działający w czasie rzeczywistym. Robbyant, oddział Ant Group specjalizujący się w embodied AI (sztucznej inteligencji osadzonej fizycznie), właśnie udostępnił w formule open-source LingBot-Map. To nowy model bazowy 3D, który potrafi zrekonstruować szczegółowe środowiska o dużej skali na podstawie pojedynczego strumienia wideo. Co w tym najlepszego? Robi to z prędkością 20 klatek na sekundę, sprawiając, że tradycyjne metody fotogrametrii wyglądają przy nim, jakby brodziły w gęstej melasie.
„Sekretnym składnikiem” projektu jest nowatorska architektura nazwana Geometric Context Transformer (GCT). I nie jest to po prostu kolejny transformer „doklejony” na siłę do problemu wizji komputerowej. GCT zaprojektowano specjalnie po to, by uderzyć w piętę achillesową monokularnych (korzystających z jednej kamery) systemów SLAM: dryf. System sprytnie zarządza informacjami geometrycznymi za pomocą trzech równoległych mechanizmów uwagi: kotwicy kontekstowej (anchor context) dla stabilnego osadzenia współrzędnych, lokalnego okna referencyjnego dla precyzyjnych detali oraz pamięci trajektorii, która koryguje błędy na długich dystansach. Dzięki temu LingBot-Map przetwarza sekwencje przekraczające 10 000 klatek z dokładnością, która według zapewnień Robbyant pozostaje „niemal niezmienna”. Projekt jest już dostępny w serwisie GitHub. Hyperlink: Robbyant/lingbot-map
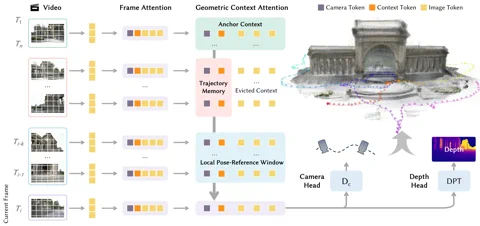
Deklarowane wyniki są, mówiąc wprost, bezczelnie dobre. W wymagającym zbiorze danych Oxford Spires model LingBot-Map osiągnął błąd trajektorii (Absolute Trajectory Error) na poziomie zaledwie 6,42 metra, co stanowi niemal 2,8-krotną poprawę względem dotychczasowego lidera wśród metod streamingowych. Co więcej, model ten prześciga nawet uznane metody offline, które mają ten luksus, że mogą przetwarzać wszystkie obrazy naraz. W benchmarku ETH3D uzyskał wynik F1 na poziomie 98,98, miażdżąc zdobywcę drugiego miejsca o ponad 21 punktów procentowych. Dla tych, których interesują techniczne „bebechy” i szczegółowa metodologia, pełna publikacja jest dostępna na arXiv. Hyperlink: Przeczytaj artykuł na arXiv
Dlaczego to ma znaczenie?
LingBot-Map to milowy krok w stronę demokratyzacji inteligencji przestrzennej. Eliminując potrzebę stosowania drogich czujników LiDAR czy skomplikowanych zestawów wielu kamer, model otwiera drzwi do taniej i wydajnej percepcji 3D w robotyce, pojazdach autonomicznych i rozszerzonej rzeczywistości (AR). Nie chodzi tu tylko o generowanie ładnych chmur punktów; chodzi o wyposażenie maszyn w ciągłe, realizowane w czasie rzeczywistym zrozumienie fizycznego świata. Jako „model bazowy 3D” wpisuje się on w szerszy trend budowania AI, która nie ogranicza się do mielenia tekstu czy obrazów, ale potrafi postrzegać, nawigować i wchodzić w interakcję ze złożonym, nieustrukturyzowanym otoczeniem – co jest absolutnym fundamentem przyszłości embodied AI.
