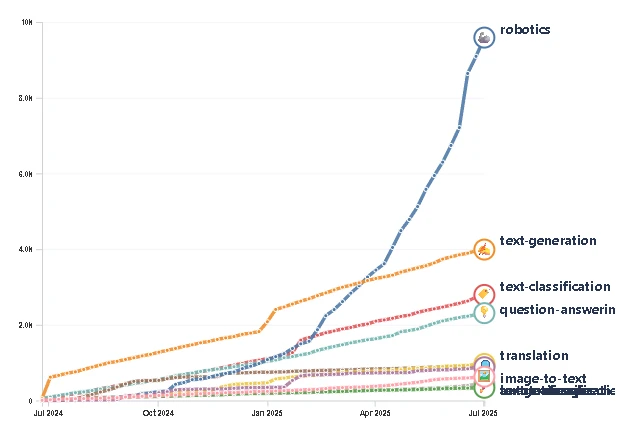
Jeśli myślicie, że najważniejszym wydarzeniem w świecie robotyki jest fakt, że dwunożna maszyna w końcu przestała się przewracać o własne nogi, to patrzycie w złym kierunku. Coś znacznie bardziej przełomowego dzieje się nie w laboratoriach sprzętowych, a w logach danych. Prawdziwa rewolucja, która rozgrywa się na naszych oczach na platformach takich jak Hugging Face, jest napędzana przez wykładniczą eksplozję otwartych danych.
Podczas gdy duże modele językowe (LLM) od lat “ucztują”, pożerając zasoby otwartego internetu, roboty były trzymane o głodzie. One nie uczą się z tekstu; uczą się z brudnej, chaotycznej rzeczywistości świata fizycznego – z nagrań wideo, ruchów przegubów, odczytów czujników i, co najważniejsze, z własnych porażek. Historycznie te bezcenne dane były klejnotem w koronie firm robotycznych, zamkniętym w pilnie strzeżonych, korporacyjnych sejfach. Ta era właśnie dobiegła końca. W ciągu zaledwie ostatniego roku liczba zbiorów danych (datasetów) dotyczących robotyki na Hugging Face wystrzeliła z 1 145 do niemal 27 000. To skok o 2400%, który wybił tę kategorię z 44. miejsca na sam szczyt w zaledwie trzy lata, zostawiając generowanie tekstu – z jego skromnymi 5 000 zestawów – daleko w tyle.
Potop danych
To nie jest tylko zbiór hobbystycznych projektów. Wykres przygotowany przez analityka technologicznego Pierre-Alexandre’a Ballanda ilustruje prawdziwą „kambryjską eksplozję” współdzielonej wiedzy o robotach. Dane te zostały przefiltrowane tak, aby uwzględnić tylko zbiory z ponad 200 pobraniami, co oznacza, że to ogromne repozytorium jest aktywnie wykorzystywane do eksperymentów i trenowania modeli.

Ten nagły wzrost to efekt „burzy doskonałej”: tańszego przechowywania danych, lepszych narzędzi i etosu open-source ze świata AI, który w końcu przeniknął do hardware’u. Platformy takie jak Hugging Face radykalnie obniżyły próg wejścia, umożliwiając współpracę, która jeszcze pięć lat temu była nie do pomyślenia. Inicjatywy takie jak LeRobot dążą do standaryzacji formatów i narzędzi, ułatwiając każdemu wnoszenie wkładu i czerpanie korzyści ze wspólnych zasobów.
Nowi baronowie danych
Kto zatem otwiera te śluzy? Choć NVIDIA kojarzy się głównie z procesorami graficznymi, błyskawicznie staje się dominującą siłą w dziedzinie danych robotycznych. Tylko w 2025 roku otwarte zbiory danych od NVIDII pobrano ponad 9 milionów razy. Ich zestawy do post-treningu ogólnego modelu robota Isaac GR00T są najczęściej pobieranymi zasobami na całej platformie – w zeszłym roku odnotowano ich 7,9 miliona. To nie jest filantropia; to strategiczny ruch mający na celu zbudowanie fundamentów pod całą branżę i zagwarantowanie, że ich sprzęt pozostanie w samym sercu tego ekosystemu.
NVIDIA nie jest jednak osamotniona. Lista liderów w dostarczaniu danych brzmi jak „kto jest kim” w globalnym świecie AI:
- Shanghai AI Lab depcze im po piętach z imponującym wynikiem 7,6 miliona pobrań.
- Sam Hugging Face, poprzez własne inicjatywy, odpowiada za 1,4 miliona.
- Ośrodki akademickie, takie jak Stanford Vision and Learning Lab (SVL), dostarczyły zbiory pobrane ponad 710 000 razy.
- Inni kluczowi gracze to m.in. AgiBot, Yaak AI, AllenAI, a nawet producenci sprzętu, jak Unitree Robotics.

Dlaczego to jest prawdziwa rewolucja?
Przez dziesięciolecia postęp w robotyce był hamowany przez brutalną rzeczywistość: każde laboratorium musiało wymyślać koło na nowo. Zbudowanie robota, który potrafi podnieść kubek, wymagało armii doktorantów, niestandardowej maszyny i tysięcy godzin żmudnego zbierania danych. Efekt? Sztywne, wyspecjalizowane maszyny, które gubiły się w momencie, gdy przesunęło się kubek o pięć centymetrów w lewo.
Paradygmat otwartych danych rozbija to wąskie gardło:
- Obniżenie barier wejścia: Startup z nowatorskim algorytmem uczenia nie potrzebuje już zaplecza sprzętowego wartego miliony dolarów, by zacząć. Może pobrać terabajty realnych danych z dziesiątek różnych robotów i środowisk, aby trenować i testować swoje modele.
- Przyspieszenie benchmarkingu: Dzięki wspólnym zbiorom danych cała branża może wreszcie porównywać różne podejścia na równych zasadach. To pozwala oddzielić ziarno od plew i nagradzać algorytmy, które radzą sobie w zróżnicowanych, nieprzewidywalnych warunkach realnego świata.
- Efekt koła zamachowego: Więcej wysokiej jakości danych prowadzi do lepszych modeli bazowych (foundation models). Lepsze modele pozwalają na bardziej zaawansowane zastosowania, które z kolei generują jeszcze więcej i jeszcze ciekawszych danych. To samonapędzający się mechanizm, który w końcu wyprowadzi roboty z laboratoriów prosto do naszego codziennego życia.
Przyszłości robotyki nie zdefiniuje firma z najbardziej błyszczącym pancerzem robota, ale ekosystem z najbogatszymi i najbardziej zróżnicowanymi danymi. Choć tańczące humanoidy świetnie wyglądają na filmach, to właśnie ten cichy, wykładniczy wzrost współdzielonych baz danych jest fundamentem, na którym budujemy jutro. Rewolucja open-source, która odmieniła oprogramowanie, w końcu dotarła do świata fizycznego – i dzieje się to dataset po datassecie.