
Branża robotyki skrywa pewien niewygodny sekret: nauczenie robotów czegokolwiek użytecznego to proces diabelnie powolny i horrendalnie kosztowny. Przez lata dominowało przekonanie, że inteligencję należy wbijać robotom „na siłę” za pomocą modeli Vision-Language-Action (VLA), co wymaga dziesiątek tysięcy godzin, podczas których ludzie metodycznie sterują robotami, wykonując każdą możliwą czynność. To gigantyczne, wręcz epickie wąskie gardło danych.
Teraz firma robotyczna 1X proponuje rozwiązanie, które graniczy z herezją. Ich nowe podejście do humanoida NEO jest zwodniczo proste: przestańmy z tymi żmudnymi lekcjami i po prostu pozwólmy robotowi uczyć się, obserwując rozległą, chaotyczną i nieskończenie pouczającą bibliotekę ludzkich zachowań, którą nazywamy internetem. To nie jest zwykła aktualizacja; to fundamentalna zmiana w sposobie, w jaki robot może zdobywać umiejętności.
Wczorajsza bestia głodna danych
Aby w pełni docenić skok, jaki wykonuje 1X, trzeba zrozumieć status quo. Większość współczesnych modeli bazowych dla robotyki, od Helix firmy Figure po GR00T od Nvidii, to VLA. Te modele są potężne, ale nienasycenie łakną wysokiej jakości danych demonstracyjnych, specyficznych dla robotów. Oznacza to płacenie ludziom za tysiące godzin teleoperacji robotów, aby zbierać przykłady, powiedzmy, podnoszenia kubka czy składania ręcznika.
Takie podejście to poważna przeszkoda w tworzeniu prawdziwie uniwersalnych robotów. Jest drogie, słabo się skaluje, a powstałe modele mogą być kruche i zawodne, gdy napotkają obiekt lub środowisko, którego wcześniej nie widziały. To trochę jak próba nauczenia dziecka gotowania, pozwalając mu oglądać cię tylko w twojej własnej kuchni, zamiast pozwolić mu pochłonąć każdy program kulinarny, jaki kiedykolwiek powstał.
Pomarzyć o… domowych obowiązkach
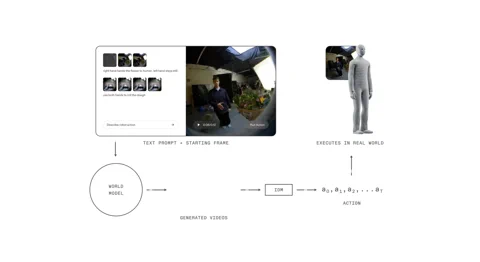
1X World Model (1XWM) całkowicie zmienia zasady gry. Zamiast bezpośrednio mapować język na działania, wykorzystuje generowanie wideo warunkowane tekstem, aby dowiedzieć się, co robić. To dwuczęściowy mózg, który skutecznie pozwala robotowi wyobrazić sobie przyszłość, zanim zacznie działać.
Po pierwsze, mamy World Model (WM), generatywny model wideo z 14 miliardami parametrów, który działa jako wyobraźnia systemu. Podajesz NEO tekstową podpowiedź – „spakuj tę pomarańczę do pojemnika na lunch” – a WM, patrząc na bieżącą scenę, kreuje krótki, wiarygodny film przedstawiający wykonanie zadania.
Następnie Inverse Dynamics Model (IDM), pragmatyk w maszynie, analizuje ten „sen”. Tłumaczy wygenerowane piksele na konkretną sekwencję poleceń ruchowych, zasypując lukę między wizualnym co a fizycznym jak. Proces ten jest ugruntowany poprzez wieloetapową strategię treningową: model zaczyna od wideo w skali internetowej, jest wstępnie trenowany na 900 godzinach egocentrycznego wideo ludzkiego, aby uzyskać perspektywę pierwszej osoby, a na koniec dostrajany na zaledwie 70 godzinach danych specyficznych dla NEO, aby dostosować się do własnego ciała.

Sprytnym trikiem w ich procesie szkoleniowym jest „upsampling napisów”. Ponieważ wiele zestawów danych wideo ma lakoniczne opisy, 1X używa VLM do generowania bogatszych, bardziej szczegółowych napisów. Zapewnia to jaśniejsze warunkowanie i poprawia zdolność modelu do wykonywania złożonych instrukcji, technikę, która wykazała podobne korzyści w modelach obrazów, takich jak DALL-E 3 od OpenAI.
Przewaga humanoida
Całe to podejście, stawiające wideo na pierwszym miejscu, opiera się na kluczowym, i być może oczywistym, elemencie sprzętowym: robot ma kształt człowieka. 1XWM, trenowany na niezliczonych godzinach interakcji ludzi ze światem, rozwinął głębokie, domyślne zrozumienie fizycznych praw – grawitacji, pędu, tarcia, affordancji obiektów – które przenoszą się bezpośrednio, ponieważ ciało NEO porusza się w sposób fundamentalnie ludzki.
Jak to ujmuje 1X, sprzęt jest „pełnoprawnym obywatelem w stosie AI”. Kinematyczne i dynamiczne podobieństwa między NEO a człowiekiem oznaczają, że wyuczone przez model priorytetowe zasady zazwyczaj pozostają ważne. To, co model jest w stanie zwizualizować, NEO, częściej niż rzadziej, faktycznie potrafi wykonać. Ta ścisła integracja sprzętu i oprogramowania zasypuje często zdradziecką przepaść między symulacją a rzeczywistością.
Od teorii do rzeczywistości (z pewnymi potknięciami)
Wyniki są przekonujące. 1XWM pozwala NEO uogólniać zadania i obiekty, dla których nie ma żadnych bezpośrednich danych treningowych. Film promocyjny pokazuje, jak prasuje koszulę, podlewa roślinę, a nawet obsługuje deskę klozetową – zadanie, do którego nie miał wcześniej żadnych przykładów. Sugeruje to, że wiedza o dwuręcznej koordynacji i złożonej interakcji z obiektami jest skutecznie przenoszona z ludzkich danych wideo.
Ale to nie magia. System ma swoje ograniczenia. Generowane sekwencje mogą być „nadmiernie optymistyczne” co do sukcesu, a jego jednooczny pretrening może prowadzić do słabego ugruntowania 3D, powodując, że prawdziwy robot nie trafia w cel lub go przekracza, nawet gdy wygenerowany film wygląda perfekcyjnie. Wskaźniki sukcesu w zręcznych zadaniach, takich jak nalewanie płatków zbożowych czy rysowanie uśmiechniętej buźki, pozostają wyzwaniem.
Jednakże 1X znalazł obiecujący sposób na zwiększenie wydajności: obliczenia w czasie testu. W zadaniu „wyciągania chusteczki” wskaźnik sukcesu wzrósł z 30% przy pojedynczej generacji wideo do 45%, gdy systemowi pozwolono wygenerować osiem różnych możliwych przyszłości i wybrać najlepszą. Chociaż ten wybór jest obecnie ręczny, wskazuje na przyszłość, w której ewaluator VLM mógłby zautomatyzować ten proces, znacznie poprawiając niezawodność.
Samouczące się koło zamachowe
1XWM to coś więcej niż tylko przyrostowa aktualizacja; to potencjalna zmiana paradygmatu, która mogłaby szeroko otworzyć wąskie gardło danych. Tworzy koło zamachowe do samodoskonalenia. Będąc w stanie próbować szerokiego zakresu zadań z niezerowym wskaźnikiem sukcesu, NEO może teraz generować własne dane. Każda akcja, czy to sukces, czy porażka, staje się nowym przykładem treningowym, który może zostać ponownie wprowadzony do modelu w celu udoskonalenia jego polityki. Robot zaczyna uczyć się sam.
Oczywiście, nadal pozostają poważne przeszkody. WM obecnie potrzebuje 11 sekund na wygenerowanie 5-sekundowego planu, a kolejne sekundy na to, by IDM wydobył działania. Taka latencja to wieczność w dynamicznym, rzeczywistym środowisku i rozwiązanie nie do przyjęcia dla zadań reaktywnych lub delikatnej, wymagającej kontaktu manipulacji.
Mimo to, mierząc się z problemem danych bezpośrednio, 1X być może właśnie wyważył drzwi do przyszłości, w której roboty uczą się nie z naszych żmudnych instrukcji, lecz z naszego zbiorowego, zarejestrowanego doświadczenia. Ta przyszłość nabiera tempa, w rytm każdego filmiku z internetu.
