Als je denkt dat het belangrijkste nieuws in de robotica momenteel een tweevoetige robot is die toevallig niet omvalt, dan kijk je de verkeerde kant op. Er vindt een veel fundamentelere verschuiving plaats, niet in de hardware-labs, maar in de datalogboeken. Onder onze neus voltrekt zich een revolutie op platforms zoals Hugging Face, aangedreven door een exponentiële explosie van open-source data.
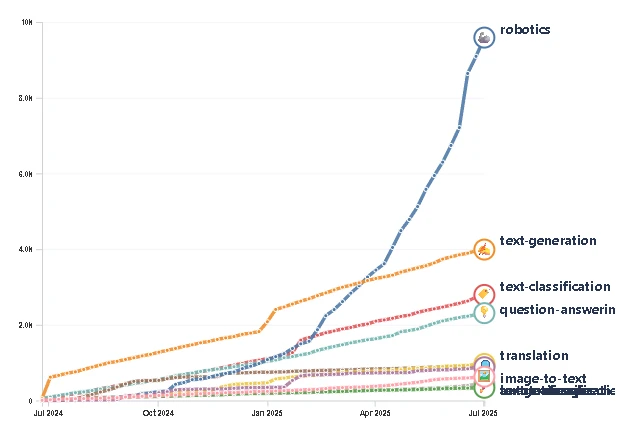
Terwijl grote taalmodellen (LLM’s) zich al jaren tegoed doen aan het open internet, stonden robots op een hongerdieet. Ze leren niet van tekst; ze leren van de weerbarstige, chaotische realiteit van de fysieke wereld: videostreams, gewrichtsbewegingen, sensordata en, misschien wel het belangrijkste, hun eigen fouten. Historisch gezien was deze kostbare data het kroonjuweel van roboticabedrijven, veilig opgeborgen in bedrijfseigen kluizen. Dat tijdperk is nu definitief voorbij. In slechts één jaar tijd is het aantal robotica-datasets op Hugging Face gekatapulteerd van 1.145 naar bijna 27.000. Dat is een stijging van maar liefst 2.400%. Hiermee is de categorie in drie jaar tijd van de 44e plek naar de absolute nummer één gestegen, waarmee het zelfs tekstgeneratie (met ‘slechts’ 5.000 datasets) ver achter zich laat.
De data-zondvloed
Dit is niet zomaar een verzameling hobbyprojecten. De grafiek, afkomstig van tech-analist Pierre-Alexandre Balland, toont een ‘Cambrische explosie’ van gedeelde robotkennis. De data is gefilterd om alleen datasets met meer dan 200 downloads mee te tellen, wat aangeeft dat deze enorme opslagplaats ook echt actief wordt gebruikt voor experimenten en het trainen van modellen.

Deze piek is het resultaat van een perfecte storm: goedkopere opslag, betere tools en de open-source ethos van de AI-wereld die eindelijk doorsijpelt naar de hardwaresector. Platforms als Hugging Face hebben de drempel om te delen radicaal verlaagd, waardoor een collaboratief ecosysteem is ontstaan dat vijf jaar geleden nog ondenkbaar was. Initiatieven zoals LeRobot proberen formaten en tools te standaardiseren, zodat het voor iedereen makkelijker wordt om bij te dragen aan en te profiteren van gedeelde data.
De nieuwe data-baronnen
Wie zetten de sluizen precies open? Hoewel je NVIDIA waarschijnlijk kent van hun GPU’s, ontpoppen ze zich razendsnel tot een dominante grootmacht in roboticadata. Alleen al in 2025 werden de open datasets van NVIDIA meer dan 9 miljoen keer gedownload. Hun datasets voor de post-training van het Isaac GR00T algemene robotmodel zijn de meest gedownloade op het hele platform, met 7,9 miljoen downloads in het afgelopen jaar. Dit is geen liefdadigheid; het is een strategische meesterzet om de fundamentele infrastructuur voor de hele sector te bouwen, waardoor hun hardware het kloppend hart van het ecosysteem blijft.
Maar ze staan niet alleen. De ranglijst van data-donateurs leest als een Who’s Who van de wereldwijde AI-top:
- Shanghai AI Lab volgt op de voet met een verbazingwekkende 7,6 miljoen downloads.
- Hugging Face zelf is via eigen initiatieven goed voor 1,4 miljoen downloads.
- Academische hubs zoals het Stanford Vision and Learning Lab (SVL) hebben datasets bijgedragen met meer dan 710.000 downloads.
- Andere grote spelers zijn onder meer AgiBot, Yaak AI, AllenAI en zelfs hardwarefabrikanten zoals Unitree Robotics.

Waarom dit de échte revolutie is
Decennialang werd de vooruitgang in de robotica belemmerd door een simpele, brute realiteit: elk lab moest het wiel opnieuw uitvinden. Om een robot een beker te laten oppakken, had je een team van PhD’s nodig, een op maat gemaakte robot en duizenden uren aan moeizame datacollectie. Het resultaat? Fragiele, taakspecifieke machines die vastliepen zodra je de beker vijf centimeter naar links verschoof.
Dit nieuwe open-data paradigma doorbreekt die flessenhals:
- De drempel voor nieuwkomers verlagen: Een startup met een briljant nieuw leeralgoritme heeft niet langer een miljoenenverslindende hardware-setup nodig om te beginnen. Ze kunnen terabytes aan real-world data downloaden van tientallen verschillende robots en omgevingen om hun modellen te trainen en te valideren.
- Snellere benchmarking: Dankzij gedeelde datasets kan de hele sector nu verschillende benaderingen vergelijken op een gelijk speelveld. Het scheidt het kaf van het koren en beloont algoritmen die goed generaliseren in diverse, rommelige praktijksituaties.
- Het vliegwieleffect: Meer kwalitatieve data leidt tot betere basismodellen (foundation models). Betere modellen maken complexere toepassingen mogelijk, die op hun beurt weer meer – en interessantere – data genereren. Deze virtueuze cirkel is de motor die robotica eindelijk uit het lab en naar ons dagelijks leven zal brengen.
De toekomst van de robotica wordt niet bepaald door het bedrijf met de meest glimmende hardware, maar door het ecosysteem met de rijkste en meest diverse data. Hoewel dansende humanoïden het goed doen in video’s, is de stille, exponentiële groei van gedeelde datasets de echte infrastructuur die nu wordt aangelegd. De open-source revolutie die software transformeerde, is eindelijk gearriveerd in de fysieke wereld – dataset voor dataset.