
De robotica-industrie heeft een ongemakkelijk geheim: robots iets nuttigs leren doen is tergend traag en kolossaal duur. Jarenlang was de heersende gedachte om intelligentie er met grof geweld in te stampen met behulp van Vision-Language-Action (VLA) modellen, die tienduizenden uren van mensen vereisen die robots minutieus door elke denkbare taak loodsen. Een data-flessenhals van epische proporties.
Nu stelt roboticafirma 1X een oplossing voor die grenst aan ketterij. Hun nieuwe aanpak voor de NEO-humanoïde is bedrieglijk eenvoudig: stop met de moeizame lessen en laat de robot gewoon leren door te kijken naar de enorme, chaotische en eindeloos leerzame bibliotheek van menselijk gedrag die we het internet noemen. Dit is niet zomaar een upgrade; het is een fundamentele verschuiving in hoe een robot vaardigheden kan verwerven.
Het datahongerige beest van gisteren
Om de sprong die 1X maakt echt te waarderen, moeten we eerst even stilstaan bij de huidige situatie. De meeste moderne funderingsmodellen voor robotica, van Figure’s Helix tot Nvidia’s GR00T, zijn VLA’s. Deze modellen zijn krachtig, maar ze zijn onverzadigbaar hongerig naar hoogwaardige, robotspecifieke demonstratiedata. Dit betekent dat mensen duizenden uren robots moeten tele-opereren om voorbeelden te verzamelen van, zeg, het oppakken van een kopje of het opvouwen van een handdoek.
Deze aanpak is een grote belemmering voor het creëren van echt algemeen inzetbare robots. Het is duur, het schaalt niet goed, en de resulterende modellen kunnen kwetsbaar zijn, falend wanneer ze worden geconfronteerd met een object of omgeving die ze nog nooit eerder hebben gezien. Het is alsof je een kind probeert te leren koken door het alleen in je eigen keuken te laten meekijken, in plaats van het alle kookprogramma’s ter wereld te laten bingewatchen.
Droom een beetje over… klusjes doen
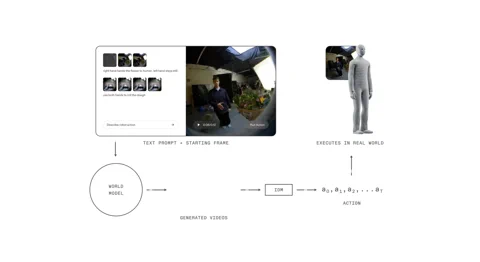
Het 1X World Model (1XWM) gooit dat hele speelboek overboord. In plaats van taal direct te koppelen aan acties, gebruikt het tekst-geconditioneerde videogeneratie om te bepalen wat te doen. Het is een tweedelig brein dat de robot effectief in staat stelt de toekomst te verbeelden voordat hij handelt.
Eerst is er het World Model (WM), een generatief videomodel met 14 miljard parameters dat fungeert als de verbeelding van het systeem. Je geeft NEO een tekstprompt – “pak deze sinaasappel in de lunchbox” – en de WM, kijkend naar de huidige scène, droomt een korte, geloofwaardige video op van de voltooide taak.
Dan analyseert het Inverse Dynamics Model (IDM), de pragmaticus in de machine, die droom. Het vertaalt de gegenereerde pixels naar een concrete reeks motorische commando’s, waarbij de kloof wordt overbrugd tussen een visueel wat en een fysiek hoe. Dit proces is gebaseerd op een meerfasige trainingsstrategie: het model begint met video’s op webschaal, wordt tussentijds getraind op 900 uur egocentrische menselijke video om een eerstepersoonsperspectief te krijgen, en ten slotte fijnafgestemd op amper 70 uur NEO-specifieke data om zich aan te passen aan zijn eigen lichaam.

Een slimme truc in hun trainingspijplijn is “caption upsampling”. Omdat veel videodatasets beknopte beschrijvingen hebben, gebruikt 1X een VLM om rijkere, gedetailleerdere bijschriften te genereren. Dit zorgt voor een duidelijkere conditionering en verbetert het vermogen van het model om complexe instructies te volgen, een techniek die vergelijkbare voordelen heeft getoond in beeldmodellen zoals OpenAI’s DALL-E 3.
Het humanoïde voordeel
Deze hele video-eerst-aanpak hangt af van een cruciaal, en misschien zelfs voor de hand liggend, stukje hardware: de robot is gevormd als een mens. De 1XWM, getraind op talloze uren van mensen die interactie hebben met de wereld, heeft een diep, impliciet begrip ontwikkeld van natuurkundige wetmatigheden – zwaartekracht, momentum, wrijving, objectaffordances – die direct overdraagbaar zijn omdat NEO’s lichaam op een fundamenteel mensachtige manier beweegt.
Zoals 1X het stelt, is de hardware een “eersteklas burger in de AI-stack”. De kinematische en dynamische overeenkomsten tussen NEO en een mens betekenen dat de aangeleerde basisprincipes van het model over het algemeen geldig blijven. Wat het model kan visualiseren, kan NEO, vaker wel dan niet, ook daadwerkelijk uitvoeren. Deze nauwe integratie van hardware en software dicht de vaak verraderlijke kloof tussen simulatie en werkelijkheid.
Van theorie naar realiteit (met wat struikelblokken)
De resultaten zijn overtuigend. 1XWM stelt NEO in staat te generaliseren naar taken en objecten waarvoor het nul directe trainingsdata heeft. De promotievideo toont hoe het een overhemd strijkt, een plant water geeft en zelfs een toiletbril bedient – een taak waarvoor het geen eerdere voorbeelden had. Dit suggereert dat de kennis voor tweehands coördinatie en complexe objectinteractie succesvol wordt overgedragen vanuit de menselijke videodata.
Maar dit is geen magie. Het systeem heeft zijn beperkingen. Gegenereerde ‘rollouts’ kunnen “overdreven optimistisch” zijn over succes, en de monoculaire voortraining kan leiden tot zwakke 3D-verankering, waardoor de echte robot een doelwit onderschiet of overschiet, zelfs als de gegenereerde video er perfect uitziet. Succespercentages bij behendige taken zoals ontbijtgranen inschenken of een smiley tekenen blijven een uitdaging.
1X heeft echter een veelbelovende manier gevonden om de prestaties te verbeteren: rekenkracht tijdens de testfase. Voor een taak om een tissue te pakken, sprong het succespercentage van 30% bij één videogeneratie naar 45% toen het systeem acht verschillende mogelijke toekomsten mocht genereren en de beste selecteren. Hoewel deze selectie momenteel handmatig is, wijst het op een toekomst waarin een VLM-evaluator het proces zou kunnen automatiseren, waardoor de betrouwbaarheid aanzienlijk verbetert.
Het zelflerende vliegwiel
De 1XWM vertegenwoordigt meer dan een incrementele update; het is een potentiële paradigmaverschuiving die de data-flessenhals definitief kan doorbreken. Het creëert een vliegwiel voor zelfverbetering. Door een breed scala aan taken met een niet-nul succespercentage te kunnen uitvoeren, kan NEO nu zijn eigen data genereren. Elke actie, of het nu een succes of een mislukking is, wordt een nieuw trainingsexemplaar dat teruggevoerd kan worden naar het model om zijn beleid te verfijnen. De robot begint zichzelf te onderwijzen.
Natuurlijk blijven er grote hindernissen bestaan. De WM heeft momenteel 11 seconden nodig om een plan van 5 seconden te genereren, met nog een seconde voor het IDM om de acties te extraheren. Die latentie is een eeuwigheid in een dynamische, real-world omgeving en een absolute ’no-go’ voor reactieve taken of delicate, contactrijke manipulatie.
Toch, door het dataprobleem rechtstreeks aan te pakken, heeft 1X misschien net de deur opengegooid naar een toekomst waarin robots niet leren van onze moeizame instructies, maar van onze collectieve, vastgelegde ervaring. Die toekomst versnelt, video na video.
