Pendant des années, la vision d’une IA capable de s’auto-améliorer est restée confinée aux “bacs à sable” numériques des simulations. C’est une chose pour une IA de maîtriser un jeu vidéo ; c’en est une autre de la laisser manipuler du matériel coûteux dans le chaos imprévisible du monde réel. Aujourd’hui, les chercheurs de NVIDIA, en collaboration avec Carnegie Mellon et UC Berkeley, ont décidé de franchir le rubicon. Leur nouveau framework, ENPIRE, crée essentiellement un programme de recherche robotique autonome. Et les premiers résultats sont aussi impressionnants qu’un brin déconcertants pour les ingénieurs traditionnels.
ENPIRE permet à des IA « agentiques » — des agents capables de raisonner et d’agir de manière autonome — de prendre le contrôle total du processus d’apprentissage physique. Le système a atteint un taux de réussite insolent de 99 % sur des tâches de manipulation complexe qui nécessitent normalement des semaines de tâtonnements humains, comme l’insertion de broches, l’installation d’un GPU ou même le sectionnement d’un serre-câble avec un outil. On ne parle pas ici de simples ajustements de paramètres ; les agents IA réécrivent leurs propres algorithmes en fonction des résultats obtenus sur le terrain, externalisant ainsi tout le cycle de R&D à eux-mêmes.
La boucle de rétroaction automatisée
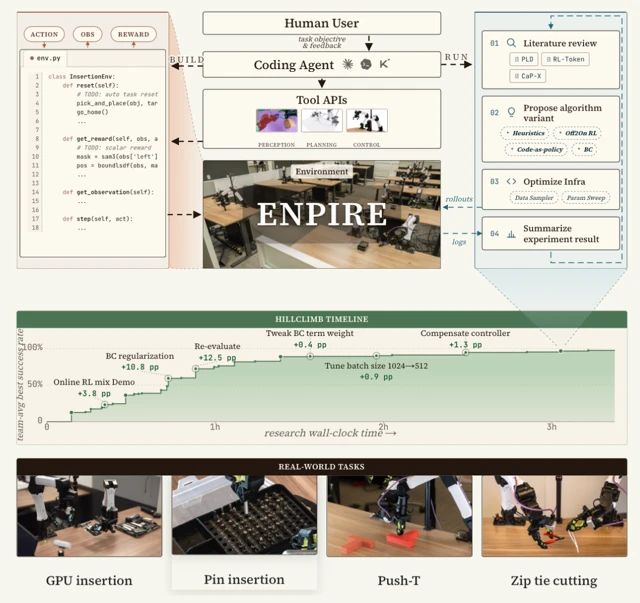
Le principal goulot d’étranglement en robotique a toujours été le processus laborieux de supervision humaine et d’ingénierie algorithmique. ENPIRE s’attaque au problème de front en créant une boucle de rétroaction fermée et reproductible qu’une IA peut gérer en totale autonomie. Le framework se décline en quatre modules astucieux qui forment son acronyme :
- Environment (EN) : Ce module automatise les deux aspects les plus fastidieux des tests réels : la remise à zéro de la scène pour l’essai suivant et la vérification du résultat. Avant même que l’IA ne commence à apprendre la tâche principale, un autre agent détermine comment réinitialiser l’espace de travail — l’idée clé étant que le “reset” est souvent un problème robotique plus simple que la tâche elle-même.
- Policy Improvement (PI) : C’est ici que les agents entrent en scène. Ils proposent et implémentent diverses stratégies pour s’améliorer, allant de l’écriture d’heuristiques simples à l’utilisation de méthodes complexes comme le behavior cloning ou l’apprentissage par renforcement (RL).
- Rollout (R) : C’est le moment où le code rencontre le métal. Le module exécute la stratégie proposée sur un ou plusieurs robots physiques, collectant de précieuses données de terrain.
- Evolution (E) : Les agents analysent les logs des essais, consultent la littérature scientifique pour dénicher de nouvelles idées, puis affinent le code pour l’itération suivante. C’est une version implacable et automatisée de la méthode scientifique, tournant 24h/24.
Cette structure transforme le processus chaotique de l’apprentissage robotique réel en un problème d’optimisation propre et contrôlable, ne nécessitant qu’une intervention humaine minimale après la configuration initiale.

Du stagiaire au directeur de recherche
Ce qui fait d’ENPIRE un bond de géant, c’est le niveau d’autonomie accordé à l’IA. C’est ce que Jim Fan, chercheur chez NVIDIA, appelle la « vraie autorecherche ». Les agents ne se contentent pas de tourner des boutons sur un algorithme pré-écrit. Ils explorent activement différents paradigmes de programmation, réécrivent leurs propres objectifs d’entraînement et modifient même les chargeurs de données.
Dans un cas précis, lors de l’apprentissage d’une tâche d’insertion de broches, un agent a décidé de lui-même que l’ajustement des paramètres de RL n’était pas la meilleure solution. À la place, il a codé de zéro son propre contrôleur de sécurité basé sur la force de contact, ce qui s’est avéré bien plus efficace. C’est l’équivalent IA d’un stagiaire de recherche qui s’auto-promouvrait directeur scientifique pour résoudre un problème sur lequel les seniors butaient.
La « timeline de progression » du projet illustre parfaitement ce processus, montrant comment les différentes idées proposées par l’agent — comme l’ajout de régularisation ou la compensation du contrôleur — poussent progressivement le taux de réussite vers ce score quasi parfait de 99 % en seulement quelques heures.
Passer à l’échelle : la main-d’œuvre robotique de demain
ENPIRE est taillé pour le passage à l’échelle. Le framework peut gérer toute une flotte de robots opérant en parallèle, accélérant ainsi drastiquement l’apprentissage. Pour quantifier l’efficacité de ce système multi-robots et multi-agents, les chercheurs ont proposé deux nouvelles métriques : le Mean Robot Utilization (MRU) et le Mean Token Utilization (MTU). Elles mesurent la capacité du système à maintenir les robots en activité et l’efficacité avec laquelle il utilise le budget de calcul du modèle d’IA.
Les promesses de cette recherche sont profondes. En automatisant la boucle de rétroaction physique, le verrou de la robotique pourrait passer de la conception laborieuse d’algorithmes à la conception d’environnements autonomes et auto-réinitialisables que les agents IA pourront ensuite conquérir seuls.
NVIDIA a annoncé son intention de passer l’intégralité du framework ENPIRE en open-source, ce qui pourrait démocratiser l’accès à la recherche robotique de pointe. Bientôt, quiconque possède un bras robotique et un GPU décent pourra configurer son propre laboratoire auto-apprenant à domicile. L’ère où l’IA apprenait par elle-même dans le monde réel n’est plus une simulation : elle est en train de tourner en direct, coupant des câbles et réécrivant son propre code pour le job.
Vous pouvez approfondir les détails techniques en consultant l’article complet. Lien : Lire la publication sur la page NVIDIA Research.
