
Parlons un peu de l’éléphant qui encombre la salle blanche. Alors que les capital-risqueurs se bousculent pour financer la prochaine merveille bipède, une vérité aussi silencieuse qu’accablante se cache sous nos yeux : malgré les milliards investis, la somme de travail réellement utile accomplie par cette nouvelle vague de robots avancés relève, pour rester poli, de l’erreur d’arrondi.
Dans un récent compte-rendu d’une franchise brutale, Yang York, cofondateur de Dyna, a passé le battage médiatique au scalpel, et le portrait qu’il en tire n’est pas beau à voir. Oubliez les vidéos léchées de robots faisant du parkour ou manipulant un œuf avec délicatesse. La réalité est dans les chiffres, et ils racontent une déconnexion profonde. Entre 2022 et 2025, l’industrie de la robotique a englouti plus de 18 milliards de dollars de financement. Pourtant, en ce début d’année 2026, l’impact dans le monde réel reste infinitésimal.
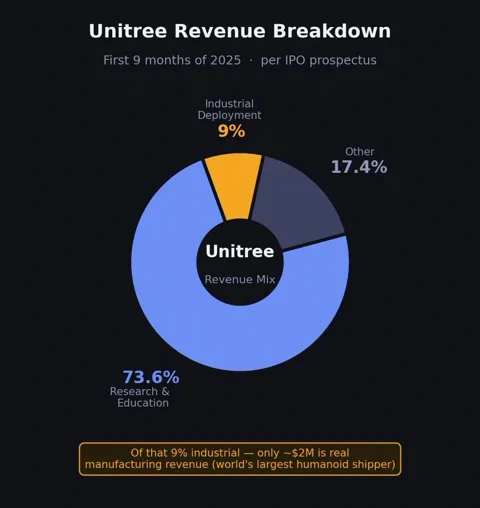
York pointe du doigt les figures de proue de ce boom du hardware. Lors d’une conférence sur les résultats en janvier 2026, Elon Musk a admis que pratiquement aucun robot Optimus de Tesla n’effectuait de tâche utile dans ses usines. Et Unitree, sans doute le plus gros vendeur d’humanoïdes au monde, a révélé dans son prospectus d’introduction en bourse en mars que 73,6 % de son chiffre d’affaires provenait de la recherche et de l’éducation. Le déploiement industriel réel ? À peine 9 %, dont l’essentiel se résume à des fonctions d’accueil ou de guide touristique. Les revenus provenant de vraies tâches de fabrication s’élèvent à un dérisoire montant de 2 millions de dollars environ.
Ce gouffre entre les attentes financières et la réalité physique est ce que York appelle la bulle. Et la question n’est pas de savoir si la technologie finira par fonctionner un jour. C’est une question de calendrier. Comme il le dit lui-même : « Une bulle, c’est l’écart entre les capacités techniques actuelles et les attentes humaines, multiplié par le temps. »
Votre analogie avec les LLM est mauvaise, et vous devriez avoir honte
L’un des piliers de l’argumentation de York est que l’industrie de la robotique s’enivre de mauvaises analogies. Les investisseurs et les fondateurs, grisés par la croissance exponentielle des grands modèles de langage (LLM), tentent d’appliquer la même recette au monde des atomes, et c’est un échec spectaculaire.
Les LLM ont changé d’échelle à la vitesse de l’éclair parce qu’ils sont purement logiciels, distribués instantanément à des milliards de personnes via Internet. Les robots, eux, sont physiques. Ils cassent. Ils nécessitent de la maintenance. Ils doivent naviguer dans le chaos imprévisible et sale du monde réel.
L’analogie la plus tentante, et tout aussi bancale, est celle des véhicules autonomes (AV). Mais là encore, le compte n’y est pas. Une voiture est utile même sans conduite autonome ; c’est une catégorie de produit établie, un canal de distribution qui n’attend qu’une mise à jour de son IA. Un humanoïde sans intelligence, ironise York, c’est « une machine de 27 kg avec 28 degrés de liberté et aucune utilité. » Il n’a pas de base d’utilisateurs intégrée. Il n’y a pas de parc installé à mettre à jour. L’industrie essaie de construire l’application, le téléphone et le réseau mobile en même temps.
Cela signifie que la robotique n’aura pas une courbe de décollage en forme de LLM. Elle n’aura même pas une courbe façon véhicule autonome. Elle aura une courbe de robotique, et le refus de l’industrie d’accepter cette réalité est son erreur la plus coûteuse.
Les trois grands mensonges de la robotique moderne
York identifie trois sophismes fondamentaux qui soutiennent la bulle spéculative. Ce sont les petits mensonges que l’industrie se raconte à elle-même en encaissant un nouveau chèque à neuf chiffres.
1. Le hardware n’est pas un canal de distribution
L’idée reçue la plus onéreuse est de croire qu’expédier un robot physique revient à construire un canal de distribution. La logique est la suivante : placez le matériel chez le client, et le reste suivra. C’est une erreur fatale.
Un véritable canal crée une valeur récurrente. Si un robot fait une démonstration puis prend la poussière parce qu’il ne rentre pas dans les clous du ROI (retour sur investissement), vous n’avez pas de canal. Vous avez un presse-papier de luxe. York soutient qu’un vrai canal robotique est un système de déploiement complet : évaluation du site, définition des tâches, capture des données, débogage à distance et mises à jour continues.
« Le test d’un canal est de savoir si le prochain déploiement est plus rapide que le précédent », écrit York. « Si ce n’est pas le cas, vous n’avez pas construit un canal. Vous avez construit du stock et de la comm’. »

2. Votre « Foundation Model » n’est qu’une fondation
La deuxième erreur est une mécompréhension de la manière dont les modèles d’IA s’améliorent réellement. Toute la conversation en robotique a tourné autour du pré-entraînement sur des jeux de données massifs. Mais l’ingrédient secret des LLM modernes n’est pas seulement le pré-entraînement ; c’est la boucle itérative serrée entre le pré-entraînement et le retour d’expérience post-entraînement spécifique au domaine.
La robotique a peine entamé cette boucle. La plupart des équipes gavent les modèles de données en espérant qu’une capacité en émerge par miracle. Mais sans le signal post-entraînement provenant de déploiements réels — de robots qui échouent concrètement dans une usine — les modèles ne peuvent pas mûrir. Il n’existe pas de métrique unifiée, comme la « perplexité » pour un LLM, sur laquelle s’optimiser. Un modèle qui survole les tests de référence en laboratoire est inutile s’il ne sait pas gérer les changements de luminosité dans un véritable entrepôt.
3. Le volant d’inertie est fait de choses ennuyeuses
Cela nous mène à la partie la plus sous-estimée de l’édifice : l’infrastructure de déploiement elle-même. Il ne s’agit pas seulement de vente ; c’est le travail d’ingénierie ingrat et peu glamour qui consiste à transformer un déploiement unique en un actif réutilisable et évolutif. Ce sont les outils de diagnostic à distance, l’acheminement des données et la fiabilité des mises à jour.
Sans ce « volant d’inertie », tout le système s’enraye. Le robot ne pénètre pas dans des environnements réels. Le modèle ne reçoit pas les données du terrain dont il a besoin pour progresser. La courbe de capacité stagne, peu importe la puissance de calcul injectée. La bulle, selon York, « réside dans l’écart entre les équipes qui ont compris cela et celles qui optimisent encore des scores de référence et des vidéos de démo. »
La seule issue est d’aller au bout
Face à ce constat, le secteur s’est scindé. Certains privilégient le modèle d’abord, pariant qu’un « cerveau » suffisamment puissant résoudra tout et que le hardware deviendra un produit de base. D’autres privilégient le hardware d’abord, convaincus qu’un corps parfait est la clé et que les logiciels open-source combleront les lacunes.
York et Dyna se situent fermement dans le troisième camp : l’intégration verticale. Ils n’ont pas choisi cette voie parce qu’elle est à la mode, mais parce qu’après un an de déploiement de leur modèle DYNA-1, ils ont réalisé que l’alternative était impossible. Ils ont appris à la dure que le déploiement ne devient pas magiquement plus simple avec le temps. La boucle de rétroaction doit se refermer simultanément sur la recherche, le hardware et le déploiement.
C’est là que se situe le travail à venir. Il ne s’agit pas de courir après la prochaine démo virale. Il s’agit du processus méticuleux consistant à bâtir un système qui rend le dixième déploiement plus rapide et plus fiable que le premier. La première équipe qui parviendra réellement à craquer ce code ne se contentera pas de gagner le marché : elle le définira. En attendant, nous ne sommes que les spectateurs d’une fête de la science extrêmement coûteuse.
