
L’industrie de la robotique a un sale petit secret : enseigner aux robots comment faire quoi que ce soit d’utile est atrocement lent et incroyablement coûteux. Pendant des années, la sagesse populaire a été de forcer l’intelligence brute avec des modèles Vision-Langage-Action (VLA), qui exigent des dizaines de milliers d’heures d’humains manipulant méticuleusement des robots à travers toutes les tâches imaginables. C’est un goulot d’étranglement de données aux proportions épiques.
Aujourd’hui, la firme de robotique 1X propose une solution qui frise l’hérésie. Leur nouvelle approche pour l’humanoïde NEO est d’une simplicité trompeuse : arrêter les leçons laborieuses et laisser simplement le robot apprendre en observant la vaste, chaotique et infiniment instructive bibliothèque de comportements humains que nous appelons Internet. Ce n’est pas seulement une mise à niveau ; c’est un changement fondamental dans la manière dont un robot peut acquérir des compétences.
La bête affamée de données d’hier
Pour apprécier le saut que 1X est en train de faire, il faut comprendre le statu quo. La plupart des modèles fondation modernes pour la robotique, de Helix de Figure à GR00T de Nvidia, sont des VLA. Ces modèles sont puissants, mais ils sont insatiablement gourmands en données de démonstration de haute qualité, spécifiques aux robots. Cela signifie qu’il faut payer des gens pour téléopérer des robots pendant des milliers d’heures afin de collecter des exemples, par exemple, de ramassage d’une tasse ou de pliage d’une serviette.
Cette approche est un obstacle majeur à la création de robots véritablement polyvalents. Elle est coûteuse, elle ne passe pas à l’échelle et les modèles qui en résultent peuvent être fragiles, échouant face à un objet ou un environnement qu’ils n’ont jamais rencontrés. C’est comme essayer d’apprendre à un enfant à cuisiner en le laissant uniquement vous observer dans votre propre cuisine, au lieu de le laisser se gaver de toutes les émissions de cuisine jamais produites.
Rêver un petit rêve de… faire les corvées
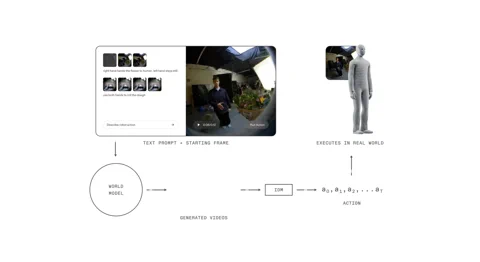
Le 1X World Model (1XWM) jette ce manuel par la fenêtre. Au lieu de mapper directement le langage aux actions, il utilise la génération vidéo conditionnée par le texte pour déterminer quoi faire. C’est un cerveau en deux parties qui permet efficacement au robot d’imaginer l’avenir avant d’agir.
Premièrement, il y a le World Model (WM), un modèle vidéo génératif de 14 milliards de paramètres qui agit comme l’imagination du système. Vous donnez à NEO une invite textuelle – “mets cette orange dans la boîte à lunch” – et le WM, observant la scène actuelle, imagine une courte vidéo plausible de la tâche en cours d’achèvement.
Ensuite, l’Inverse Dynamics Model (IDM), le pragmatique de la machine, analyse ce rêve. Il traduit les pixels générés en une séquence concrète de commandes motrices, comblant l’écart entre un quoi visuel et un comment physique. Ce processus est ancré grâce à une stratégie d’entraînement en plusieurs étapes : le modèle commence avec des vidéos à l’échelle du web, est entraîné à mi-parcours sur 900 heures de vidéos humaines égocentriques pour obtenir une perspective à la première personne, et enfin affiné sur seulement 70 heures de données spécifiques à NEO pour s’adapter à son propre corps.

Une astuce astucieuse dans leur pipeline d’entraînement est le “suréchantillonnage des légendes”. Étant donné que de nombreux jeux de données vidéo ont des descriptions laconiques, 1X utilise un VLM pour générer des légendes plus riches et détaillées. Cela fournit un conditionnement plus clair et améliore la capacité du modèle à suivre des instructions complexes, une technique qui a montré des avantages similaires dans les modèles d’image comme DALL-E 3 d’OpenAI.
L’avantage humanoïde
Cette approche vidéo-d’abord repose sur un élément matériel critique, et peut-être évident : le robot a la forme d’une personne. Le 1XWM, entraîné sur d’innombrables heures d’humains interagissant avec le monde, a développé une compréhension profonde et implicite des principes physiques fondamentaux – gravité, élan, friction, affordances des objets – qui se transfèrent directement car le corps de NEO se meut d’une manière fondamentalement humaine.
Comme le dit 1X, le matériel est un “citoyen de première classe dans la pile d’IA”. Les similitudes cinématiques et dynamiques entre NEO et un humain signifient que les principes appris du modèle restent généralement valides. Ce que le modèle peut visualiser, NEO peut, le plus souvent, réellement le faire. Cette intégration étroite du matériel et du logiciel comble le fossé souvent périlleux entre la simulation et la réalité.
De la théorie à la réalité (avec quelques embûches)
Les résultats sont convaincants. Le 1XWM permet à NEO de se généraliser à des tâches et des objets pour lesquels il n’a aucune donnée d’entraînement directe. La vidéo promotionnelle le montre repassant une chemise, arrosant une plante, et même manipulant un siège de toilette – une tâche pour laquelle il n’avait aucun exemple préalable. Cela suggère que les connaissances en coordination bimanuelle et en interaction complexe avec les objets sont transférées avec succès à partir des données vidéo humaines.
Mais ce n’est pas de la magie. Le système a ses limites. Les déroulements générés peuvent être “excessivement optimistes” quant au succès, et son pré-entraînement monoculaire peut entraîner une faible compréhension spatiale en 3D, ce qui amène le robot réel à manquer ou dépasser une cible même lorsque la vidéo générée semble parfaite. Les taux de réussite sur des tâches de dextérité comme verser des céréales ou dessiner un smiley restent un défi.
Cependant, 1X a trouvé un moyen prometteur d’améliorer les performances : le calcul au moment du test. Pour une tâche de “tirer un mouchoir”, le taux de réussite est passé de 30 % avec une seule génération vidéo à 45 % lorsque le système a été autorisé à générer huit futurs possibles différents et à sélectionner le meilleur. Bien que cette sélection soit actuellement manuelle, elle pointe vers un avenir où un évaluateur VLM pourrait automatiser le processus, améliorant considérablement la fiabilité.
La boucle vertueuse de l’auto-apprentissage
Le 1XWM représente plus qu’une mise à jour incrémentale ; c’est un changement de paradigme potentiel qui pourrait faire éclater le goulot d’étranglement des données. Il crée une boucle vertueuse d’auto-amélioration. En étant capable de tenter un large éventail de tâches avec un taux de réussite non nul, NEO peut désormais générer ses propres données. Chaque action, qu’elle soit réussie ou échouée, devient un nouvel exemple d’entraînement qui peut être réinjecté dans le modèle pour affiner sa politique. Le robot commence à s’enseigner lui-même.
Bien sûr, des obstacles majeurs subsistent. Le WM prend actuellement 11 secondes pour générer un plan de 5 secondes, avec une seconde supplémentaire pour l’IDM afin d’extraire les actions. Ce temps de latence est une éternité dans un environnement dynamique et réel et un non-départ pour les tâches réactives ou la manipulation délicate et riche en contacts.
Pourtant, en s’attaquant de front au problème des données, 1X pourrait bien avoir ouvert grand la porte à un avenir où les robots apprennent non pas de nos instructions fastidieuses, mais de notre expérience collective et enregistrée. Cet avenir s’accélère, une vidéo Internet à la fois.
