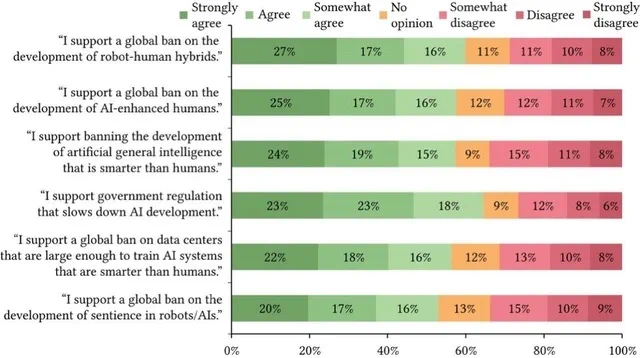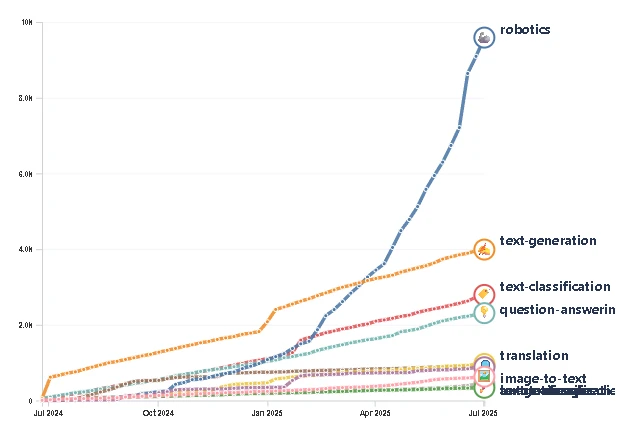
Si vous pensez que l’actualité la plus brûlante de la robotique se résume à un humanoïde bipède qui parvient à ne pas s’étaler de tout son long, vous faites fausse route. Un séisme bien plus puissant est en train de secouer le secteur, et il ne se passe pas dans les laboratoires de mécanique, mais dans les journaux de données. Une révolution progresse à bas bruit, sous nos yeux, sur des plateformes comme Hugging Face, propulsée par une explosion exponentielle de données en open source.
Alors que les grands modèles de langage (LLM) se gavent de l’Internet ouvert depuis des années, les robots, eux, étaient au régime sec. Ils n’apprennent pas avec du texte ; ils se nourrissent de la réalité complexe et chaotique du monde physique : flux vidéo, mouvements d’articulations, flux de capteurs et, surtout, les échecs. Historiquement, ces précieuses données étaient le joyau de la couronne des entreprises de robotique, jalousement gardées dans des coffres-forts propriétaires. Cette ère est officiellement révolue. En seulement un an, le nombre de jeux de données (datasets) robotiques sur Hugging Face est passé de 1 145 à près de 27 000. Une augmentation fulgurante de 2 400 %, propulsant cette catégorie de la 44e à la 1ère place en trois ans, loin devant la génération de texte qui stagne à “seulement” 5 000 datasets.
Le déluge de données
Il ne s’agit pas ici d’une simple accumulation de projets d’amateurs. Le graphique, gracieusement fourni par l’analyste technologique Pierre-Alexandre Balland, illustre une véritable “explosion cambrienne” du savoir robotique partagé. Ces chiffres ne concernent que les jeux de données ayant dépassé les 200 téléchargements, preuve que ce vaste réservoir est activement utilisé pour l’expérimentation et l’entraînement de modèles.

Cette déferlante est le résultat d’un alignement de planètes parfait : baisse des coûts de stockage, meilleurs outils de développement et l’esprit open source de l’IA qui contamine enfin le monde du hardware. Des plateformes comme Hugging Face ont radicalement réduit les frictions liées au partage, créant un écosystème collaboratif impensable il y a encore cinq ans. Des initiatives comme LeRobot visent à standardiser les formats et les outils, permettant à chacun de contribuer et de profiter de cette intelligence collective.
Les nouveaux barons de la donnée
Alors, qui ouvre ainsi les vannes ? Si vous connaissez NVIDIA pour ses processeurs graphiques, sachez que la firme devient rapidement une force dominante dans la donnée robotique. Rien qu’en 2025, les datasets ouverts de NVIDIA ont été téléchargés plus de 9 millions de fois. Leurs jeux de données destinés au post-entraînement du modèle généraliste Isaac GR00T sont les plus prisés de toute la plateforme, avec 7,9 millions de téléchargements l’an dernier. Ce n’est pas de la philanthropie, c’est un coup de maître stratégique : en bâtissant l’infrastructure fondamentale du secteur, ils s’assurent que leur matériel reste le cœur battant de l’écosystème.
Mais ils ne sont pas seuls. Le classement des contributeurs ressemble au gotha de l’IA mondiale :
- Le Shanghai AI Lab suit de près avec un chiffre impressionnant de 7,6 millions de téléchargements.
- Hugging Face elle-même, via ses propres projets, en totalise 1,4 million.
- Les centres académiques comme le Stanford Vision and Learning Lab (SVL) ont injecté des données cumulant plus de 710 000 téléchargements.
- D’autres acteurs majeurs comme AgiBot, Yaak AI, AllenAI, et même des constructeurs comme Unitree Robotics sont de la partie.

Pourquoi c’est ici que se joue la vraie révolution
Pendant des décennies, le progrès en robotique a été freiné par une réalité brutale : chaque laboratoire devait réinventer la roue. Pour apprendre à un robot à saisir une tasse, il fallait une armée de doctorants, un robot sur mesure et des milliers d’heures de collecte de données fastidieuse. Résultat ? Des machines fragiles, hyperspécialisées, incapables de fonctionner si l’on décalait la tasse de cinq centimètres vers la gauche.
Ce paradigme de la donnée ouverte fait sauter ce verrou :
- Abaisser les barrières à l’entrée : Une startup dotée d’un algorithme d’apprentissage novateur n’a plus besoin d’une installation hardware à plusieurs millions d’euros pour démarrer. Elle peut télécharger des téraoctets de données réelles provenant de dizaines de robots et d’environnements différents pour entraîner ses modèles.
- Accélérer l’étalonnage (benchmarking) : Grâce aux datasets partagés, l’ensemble du secteur peut enfin comparer les différentes approches sur un pied d’égalité. Cela permet de séparer le bon grain de l’ivraie en récompensant les algorithmes qui s’adaptent réellement au chaos du monde réel.
- Créer un cercle vertueux : Des données de haute qualité produisent de meilleurs modèles de fondation. Ces modèles permettent des applications plus sophistiquées qui, à leur tour, génèrent des données encore plus riches et variées. C’est ce moteur qui sortira enfin la robotique des laboratoires pour l’amener dans notre quotidien.
L’avenir de la robotique ne sera pas défini par l’entreprise possédant le robot le plus rutilant, mais par l’écosystème disposant des données les plus denses et les plus diversifiées. Si les vidéos d’humanoïdes dansants font le buzz, la croissance exponentielle et silencieuse des jeux de données partagés est la véritable fondation du monde de demain. La révolution open source qui a transformé le logiciel s’attaque enfin au monde physique, un dataset à la fois.