
Google DeepMind acaba de mover ficha en el tablero de la robótica con el lanzamiento de Gemini Robotics-ER 1.6, la última actualización de su modelo de “razonamiento encarnado” (Embodied Reasoning). El objetivo es ambicioso: dotar a las máquinas de esa dosis de sentido común que tanto necesitan para desenvolverse en el mundo físico. Esta nueva versión supone un salto cualitativo en la forma en que los robots ven, comprenden e interactúan con su entorno, dejando atrás la ejecución de comandos rígidos para empezar a razonar sobre sus tareas.
Una de las mejoras estrella de Gemini Robotics-ER 1.6 es su refinada comprensión visual y espacial, personificada en su nueva capacidad de “señalamiento”. Si le pides que busque una herramienta específica en un taller abarrotado de trastos, el modelo es capaz de identificar, contar y localizar los objetos correctos mientras ignora el ruido visual. No se trata solo de encontrar cosas; es la piedra angular de una lógica espacial mucho más compleja, como calcular la trayectoria perfecta para un agarre o entender órdenes relacionales del tipo “mete la llave inglesa en la caja de herramientas”. El modelo incluso puede razonar bajo restricciones lógicas, identificando, por ejemplo, qué objetos son lo suficientemente pequeños como para caber en un contenedor específico.
El modelo también aborda uno de los grandes quebraderos de cabeza de la robótica: saber cuándo un trabajo está realmente terminado. Gracias a un avanzado razonamiento multivista, Gemini Robotics-ER 1.6 puede fusionar transmisiones de vídeo en directo de varias cámaras —por ejemplo, una cenital y otra situada en la muñeca del robot— para construir una imagen completa de la escena. Esto evita que el robot entre en un bucle infinito o falle en su misión simplemente porque un objeto ha quedado oculto temporalmente desde un único ángulo de visión.
¿Por qué es esto un hito?
Esta actualización no es un simple ajuste de rendimiento; estamos hablando de construir las habilidades fundamentales para la autonomía real. La capacidad de leer manómetros analógicos, fusionar múltiples perspectivas de cámara y entender relaciones espaciales complejas es lo que diferencia a un brazo articulado de fábrica de un robot de campo verdaderamente útil. Según el anuncio oficial de DeepMind, este es, además, su modelo robótico más seguro hasta la fecha.
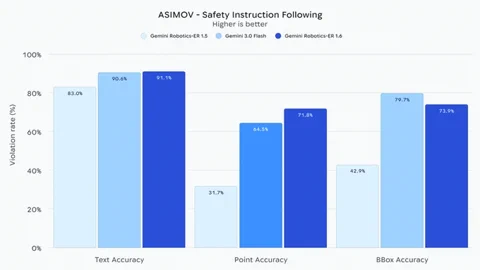
Quizás lo más relevante es que Gemini Robotics-ER 1.6 demuestra una “capacidad sustancialmente mejorada” para respetar las restricciones de seguridad física. Entiende instrucciones críticas como evitar el contacto con líquidos o no levantar objetos que superen los 20 kg. En comparación con el modelo base Gemini 3.0 Flash, se estima que es un 10% más eficaz a la hora de percibir riesgos de lesiones humanas en vídeos. Este enfoque en la seguridad y el razonamiento en el mundo real es un paso crucial hacia robots que puedan operar de forma fiable en entornos humanos impredecibles. El modelo ya está disponible para desarrolladores a través de la Gemini API y Google AI Studio.
