Si piensas que el mayor hito de la robótica actual es ver a un bípede manteniendo el equilibrio sin irse al suelo, te estás perdiendo el bosque por fijarte en el árbol. Algo mucho más sísmico está ocurriendo, y no sucede en los laboratorios de hardware, sino en los registros de datos. Una revolución silenciosa se está gestando a plena vista en plataformas como Hugging Face, impulsada por una explosión exponencial de datos de código abierto.
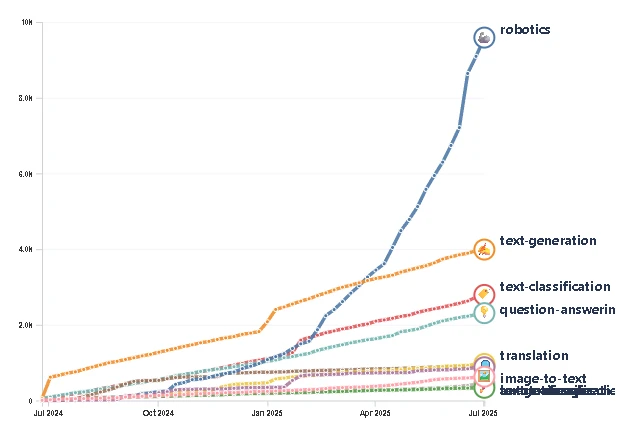
Mientras los grandes modelos de lenguaje (LLM) llevan años dándose un festín con el contenido de internet, los robots han estado a dieta forzada. Un robot no aprende leyendo párrafos; aprende de la caótica y sucia realidad del mundo físico: señales de vídeo, acciones articulares, flujos de sensores y, lo más importante, de sus propios errores. Históricamente, este “oro líquido” era la joya de la corona de las empresas de robótica, guardada bajo siete llaves en cámaras acorazadas propietarias. Esa era ha terminado. En apenas un año, el número de conjuntos de datos (datasets) de robótica en Hugging Face ha pasado de 1.145 a casi 27.000. Hablamos de un incremento del 2.400%, catapultando esta categoría del puesto 44 al número uno en solo tres años, dejando atrás incluso a la generación de texto, que se queda en unos discretos 5.000 datasets.
El tsunami de datos
No estamos ante una simple colección de proyectos de aficionados. El gráfico, cortesía del analista tecnológico Pierre-Alexandre Balland, ilustra una auténtica explosión cámbrica del conocimiento robótico compartido. Los datos están filtrados para incluir únicamente aquellos conjuntos con más de 200 descargas, lo que demuestra que este vasto repositorio se está utilizando activamente para la experimentación y el entrenamiento de modelos.

Este auge es el resultado de una “tormenta perfecta”: almacenamiento más barato, mejores herramientas y la ética del open-source del mundo de la IA que, por fin, ha permeado al hardware. Plataformas como Hugging Face han reducido drásticamente las fricciones a la hora de compartir, permitiendo un ecosistema colaborativo que hace cinco años era impensable. Iniciativas como LeRobot buscan estandarizar formatos y herramientas, facilitando que cualquiera pueda contribuir y beneficiarse del conocimiento colectivo.
Los nuevos barones de los datos
¿Quién está abriendo las compuertas? Aunque todos conocemos a NVIDIA por sus GPUs, la compañía se está convirtiendo a pasos agigantados en la fuerza dominante de los datos robóticos. Solo en 2025, sus conjuntos de datos abiertos se descargaron más de 9 millones de veces. Sus datasets para el post-entrenamiento del modelo generalista Isaac GR00T son los más descargados de toda la plataforma, con 7,9 millones de descargas en el último año. No es caridad; es un movimiento estratégico para construir la infraestructura fundacional de todo el sector, asegurándose de que su hardware siga siendo el epicentro del ecosistema.
Pero no están solos en esta carrera. La lista de los mayores contribuyentes parece un “quién es quién” de las potencias mundiales de la IA:
- Shanghai AI Lab le sigue de cerca con la asombrosa cifra de 7,6 millones de descargas.
- La propia Hugging Face, a través de sus iniciativas internas, suma 1,4 millones.
- Centros académicos como el Stanford Vision and Learning Lab (SVL) han aportado datos que superan las 710.000 descargas.
- Otros actores clave incluyen a AgiBot, Yaak AI, AllenAI, e incluso fabricantes de hardware como Unitree Robotics.

Por qué esta es la verdadera revolución
Durante décadas, el progreso en robótica estuvo lastrado por una realidad brutal: cada laboratorio tenía que reinventar la rueda. Para que un robot aprendiera a recoger una taza, se necesitaba un equipo de doctores, un robot personalizado y miles de horas de recolección manual de datos. ¿El resultado? Máquinas rígidas y ultraespecíficas que fallaban en cuanto movías la taza dos centímetros a la izquierda.
Este nuevo paradigma de datos abiertos rompe ese cuello de botella de tres formas:
- Democratización del acceso: Una startup con un algoritmo de aprendizaje brillante ya no necesita una inversión multimillonaria en hardware para empezar. Puede descargar terabytes de datos del mundo real de docenas de robots y entornos distintos para entrenar y validar sus modelos.
- Aceleración del “benchmarking”: Con datos compartidos, toda la industria puede comparar diferentes enfoques en igualdad de condiciones. Esto permite separar el grano de la paja, premiando a los algoritmos que mejor generalizan ante las condiciones caóticas del mundo real.
- El efecto volante (Flywheel Effect): Más datos de alta calidad generan mejores modelos fundacionales. Los mejores modelos permiten aplicaciones más sofisticadas que, a su vez, generan datos aún más interesantes y abundantes. Este círculo virtuoso es el motor que sacará a los robots de los laboratorios para meterlos en nuestras vidas.
El futuro de la robótica no lo definirá la empresa con el hardware más pulido, sino el ecosistema con los datos más ricos y diversos. Mientras los humanoides bailarines acaparan los vídeos virales, el crecimiento exponencial de los datos compartidos es la verdadera infraestructura que se está construyendo bajo nuestros pies. La revolución del código abierto que transformó el software ha llegado por fin al mundo físico, y está ocurriendo dataset a dataset.