
Zatímco většina z nás využívá fotoaparát v mobilu leda tak k pořizování rozmazaných momentek z koncertů, vědci z něj právě udělali plnohodnotný 3D skener pracující v reálném čase. Robbyant, divize pro vtělenou AI (embodied AI) technologického giganta Ant Group, právě uvolnila jako open-source svůj model LingBot-Map. Tento nový „3D foundation model“ dokáže rekonstruovat detailní, rozsáhlá prostředí z jediného plynulého videa. A co je na tom nejlepší? Zvládá to rychlostí 20 snímků za sekundu, což je tempo, vedle kterého vypadají tradiční metody fotogrammetrie, jako by se brodily hlubokým bahnem.
Tajemství úspěchu tkví v inovativní architektuře pojmenované Geometric Context Transformer (GCT). Nejde o jen tak nějaký transformer naroubovaný na vizuální data. GCT byl navržen specificky proto, aby vyřešil Achillovu patu monokulárních (jednokamerových) SLAM systémů: tzv. drift neboli postupné odchylování. Geometrické informace zpracovává pomocí tří paralelních mechanismů pozornosti: „anchor context“ pro stabilní ukotvení souřadnic, lokální referenční okno pro vykreslení jemných detailů a trajektorní paměť, která koriguje chyby na dlouhých trasách. Díky tomu LingBot-Map plynule zpracuje sekvence přesahující 10 000 snímků, a to s přesností, která je podle Robbyantu „téměř neměnná“. Projekt je již nyní dostupný na GitHubu. Hyperlink: Robbyant/lingbot-map
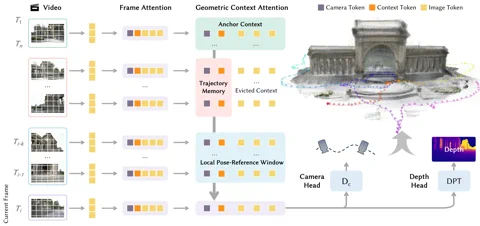
Prohlášení o výkonu jsou, upřímně řečeno, dosti odvážná. Na náročném datasetu Oxford Spires dosáhl LingBot-Map absolutní chyby trajektorie (ATE) pouhých 6,42 metru, což je téměř 2,8násobné zlepšení oproti dosud nejlepší streamovací metodě. Dokonce překonává i zavedené offline metody, které mají ten luxus, že mohou zpracovávat všechny snímky najednou. V benchmarku ETH3D pak model dosáhl F1 skóre 98,98, čímž doslova vymazal konkurenci na druhém místě o více než 21 procentních bodů. Pro ty, které zajímají syrové technické detaily, je kompletní metodika popsána v článku na serveru arXiv. Hyperlink: Read the paper on arXiv
Proč je to důležité?
LingBot-Map představuje zásadní krok směrem k demokratizaci prostorové inteligence. Tím, že eliminuje potřebu drahých LiDARů nebo složitých systémů s více kamerami, otevírá dveře pro levné a vysoce výkonné 3D vnímání v robotice, u autonomních vozidel i v rozšířené realitě. Tady nejde jen o vytváření hezkých mračen bodů; jde o to dát strojům schopnost kontinuálně a v reálném čase chápat fyzický svět kolem nich. Jakožto „3D foundation model“ je LingBot-Map součástí širšího trendu budování AI, která nezpracovává pouze text nebo obrázky, ale dokáže se orientovat a interagovat v komplexních, nestrukturovaných prostředích – což je naprostý základ pro budoucnost vtělené umělé inteligence.
