
Google DeepMind právě vytasil Gemini Robotics-ER 1.6, nejnovější update svého modelu pro „vtělené uvažování“ (Embodied Reasoning), který má robotům nadělit tolik potřebnou dávku selského rozumu pro pohyb ve fyzickém světě. Nový model výrazně posouvá schopnosti robotů vidět, chápat a interagovat s okolím – už nejde jen o tupé plnění naučených příkazů, ale o skutečné logické vyhodnocování úkolů.
Klíčovým vylepšením u Gemini Robotics-ER 1.6 je pokročilé vizuální a prostorové vnímání, které nejlépe demonstruje schopnost „ukazování“. Když robota požádáte, aby v zaplněné dílně našel konkrétní nástroj, model dokáže přesně identifikovat, spočítat a lokalizovat ty správné předměty, zatímco okolní nepořádek ignoruje. Nejde jen o prosté hledání věcí; je to základ pro komplexní prostorovou logiku, jako je plánování trajektorie pro ideální úchop nebo pochopení relačních příkazů typu „přesuň klíč do bedny s nářadím“. Model dokonce zvládne logicky vyhodnotit i fyzické limity, například určit, které objekty jsou dost malé na to, aby se vešly do konkrétní nádoby.
Model se také vypořádává s chronickým problémem robotiky: jak poznat, že je práce hotová. Díky pokročilému vícepohledovému uvažování (multi-view reasoning) dokáže Gemini Robotics-ER 1.6 propojit živý video stream z několika kamer najednou – například z té nad hlavou a z té umístěné na zápěstí – a vytvořit si tak ucelený obraz o situaci. To zabraňuje tomu, aby se robot zacyklil nebo úkol vzdal jen proto, že mu ve výhledu z jednoho úhlu zrovna něco překáží.
Proč na tom záleží?
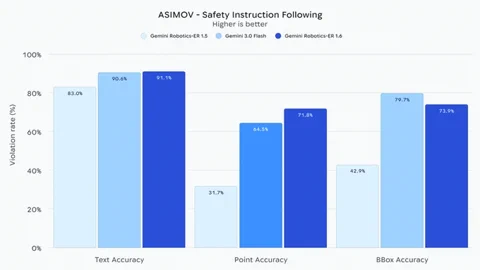
Tento update není jen drobným posunem v tabulkách výkonu; jde o budování základních dovedností pro skutečnou autonomii. Schopnost číst analogové budíky, spojovat data z více kamer a chápat složité prostorové vztahy je přesně to, co odlišuje statické tovární rameno od užitečného polního robota. Podle oficiálního oznámení DeepMindu jde navíc o jejich dosud nejbezpečnější robotický model.
Možná nejdůležitější je, že Gemini Robotics-ER 1.6 vykazuje „výrazně lepší schopnost“ dodržovat fyzikální bezpečnostní omezení. Rozumí instrukcím jako vyhýbat se kapalinám nebo nezvedat předměty těžší než 20 kg. Ve srovnání se základním modelem Gemini 3.0 Flash je údajně o 10 % lepší v rozpoznávání rizik zranění osob na videu. Tento důraz na bezpečnost a logické uvažování v reálném světě je zásadním krokem k robotům, kteří budou schopni spolehlivě a bezpečně fungovat v nepředvídatelném lidském prostředí. Model je již nyní k dispozici vývojářům prostřednictvím Gemini API a v prostředí Google AI Studio.
