Pokud žijete v přesvědčení, že největším milníkem současné robotiky je fakt, že se bipedální humanoid při chůzi nepřerazil o vlastní nohy, pak se díváte úplně špatným směrem. Přímo před našima očima se totiž odehrává tektonický posun, který neprobíhá v hardwarových laboratořích, ale v datových lozích. Na platformách jako Hugging Face právě teď tiše graduje revoluce poháněná exponenciální explozí open-source dat.
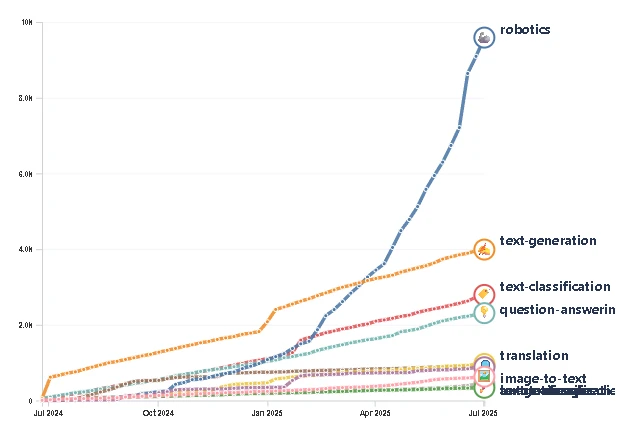
Zatímco velké jazykové modely (LLM) se už roky dosyta krmí volně dostupným internetem, roboti doposud spíše hladověli. Nenaučí se totiž nic z textu; potřebují nasát syrovou, chaotickou realitu fyzického světa – videozáznamy, trajektorie kloubů, proudy dat ze senzorů a především záznamy vlastních selhání. Historicky byla tato drahocenná data rodinným stříbrem robotických firem, zamčeným v neprodyšných trezorech. Tato éra je ale definitivně u konce. Jen za poslední rok vystřelil počet robotických datasetů na Hugging Face z 1 145 na téměř 27 000. To je nárůst o neuvěřitelných 2 400 %. Tato kategorie se během tří let katapultovala ze 44. místa na absolutní vrchol a s přehledem převálcovala i generování textu, které se drží na „pouhých“ pěti tisících datasetech.
Datová potopa
Tohle není jen sbírka nadšeneckých projektů. Graf od technologického analytika Pierra-Alexandre Ballanda ilustruje doslova kambrijskou explozi sdíleného robotického vědění. Data jsou navíc filtrována tak, aby zahrnovala pouze datasety s více než 200 staženími, což jasně ukazuje, že toto obří úložiště slouží k reálnému experimentování a trénování modelů.

Tento nárůst je výsledkem dokonalé souhry okolností: levnějšího úložiště, lepších nástrojů a étosu open-source, který z AI světa konečně prosákl i do hardwaru. Platformy jako Hugging Face radikálně snížily tření při sdílení a umožnily vznik kolaborativního ekosystému, který byl ještě před pěti lety nemyslitelný. Iniciativy jako LeRobot se navíc snaží standardizovat formáty a nástroje, čímž usnadňují komunitě přispívat i těžit ze společného know-how.
Noví datoví baroni
Kdo tedy ty stavidla otevřel? Možná znáte NVIDIA jako výrobce grafických čipů, ale firma se bleskově stává dominantní silou v robotických datech. Jen v roce 2025 byly open-source datasety od NVIDIA staženy více než devětmilionkrát. Jejich data pro post-trénink univerzálního robotického modelu Isaac GR00T jsou vůbec nejstahovanějšími na celé platformě – za poslední rok si připsala 7,9 milionu stažení. Nejde o žádnou charitu; je to strategický tah, jak vybudovat základní infrastrukturu pro celý obor a zajistit, aby jejich hardware zůstal srdcem celého ekosystému.
Nejsou v tom ale sami. Žebříček největších přispěvatelů vypadá jako seznam nejdůležitějších hráčů na poli globální AI:
- Shanghai AI Lab jim dýchá na záda s ohromujícími 7,6 miliony stažení.
- Samotný Hugging Face se skrze vlastní iniciativy podílí 1,4 miliony.
- Akademická centra jako Stanford Vision and Learning Lab (SVL) přispěla datasety s více než 710 000 staženími.
- Mezi další klíčové hráče patří AgiBot, Yaak AI, AllenAI a dokonce i výrobci hardwaru jako Unitree Robotics.

Proč je tohle ta skutečná revoluce
Po celá desetiletí byl pokrok v robotice brzděn krutou realitou: každá laboratoř musela znovu a znovu vynalézat kolo. Postavit robota, který dokáže zvednout šálek, vyžadovalo tým doktorandů, zakázkový hardware a tisíce hodin mravenčího sběru dat. Výsledek? Křehké, jednoúčelové stroje, které selhaly v momentě, kdy jste ten šálek posunuli o pět centimetrů doleva.
Tento nový paradigma otevřených dat toto úzké hrdlo rozbíjí:
- Snížení bariéry vstupu: Startup s geniálním algoritmem pro učení už nepotřebuje hardwarové vybavení za miliony dolarů, aby mohl začít. Stačí stáhnout terabajty dat z reálného světa od desítek různých robotů a prostředí a na nich své modely vytrénovat a validovat.
- Akcelerace benchmarkingu: Díky sdíleným datasetům může celý obor konečně porovnávat různé přístupy na stejném hřišti. To pomáhá oddělit zrno od plev a odměňuje algoritmy, které dokážou dobře zobecňovat v rozmanitých a neuklizených podmínkách reálného světa.
- Efekt setrvačníku: Více kvalitních dat vede k lepším základním (foundation) modelům. Lepší modely umožňují sofistikovanější aplikace, které následně generují ještě více a ještě zajímavějších dat. Tento pozitivní cyklus je motorem, který konečně dostane roboty z laboratoří do našich životů.
Budoucnost robotiky nebude definována firmou s nejnaleštěnějším hardwarem, ale ekosystémem s nejbohatšími a nejrozmanitějšími daty. Zatímco tančící humanoidi plní sociální sítě efektními videi, skutečná infrastruktura budoucnosti se staví v tichosti skrze exponenciální růst sdílených datasetů. Open-source revoluce, která od základů změnila svět softwaru, konečně dorazila do fyzické reality. A děje se to právě teď, jeden dataset za druhým.